Plano de consultas no PostgreSQL
É um tanto comum produzirmos consultas no banco de dados que acabam se tornando um problema, principalmente por produzir um tempo de resposta que não é o desejado. Geralmente precisamos dedicar um tempo para melhora-las. Neste momento é importante termos a compreensão de ações assertivas que devemos tomar, para que o resultado seja positivo e não o contrário, produzindo um resultado ainda pior. É bem possível que isso possa acontecer, pode crer! Para ajudar nesta desafio, de achar os gargalos de lentidão, temos uma ferramenta para apoiar. Pode-se fazer uso do EXPLAIN.
Essa ferramenta presente em vários SGDBs, ajuda na compreensão das ações e da sequência que a consulta será executada, e melhor, apresenta valores (números) estimados do custo de execução. Se usa ou não um índice, se vai ou não varrer todo o conjunto de dados do(s) objeto(s) envolvido(s) na busca, etc. Em resumo, a sua consulta será simulada e vai produzir um resultado, que é chamado de plano de consulta (Query Plan);
É importante estar familiarizado com o plano de consulta que a ferramenta vai produzir. Através da análise do resultado do plano, pode-se tomar ações que vão dar outro rumo a consulta, pelas melhorias a serem aplicadas.
Para cada consulta submetida ao banco, ele sempre vai seguir um plano, que é baseado entre outros nas estatísticas dos objetos, na existência de índices, do tamanho dos objetos envolvidos, paginação, uso de recurso, etc.
Neste momento a experiência pode ser um diferencial na análise e proposta das melhorias, pois poderá haver opções distintas de ações para alcançar o objetivo. Este material é uma introdução, cabe um aprofundamento para se tornar um especialista no tema.
Como usar o EXPLAIN:
EXPLAIN : Mostra o plano de execução de uma instrução
EXPLAIN [ ( option [, ...] ) ] instrução
EXPLAIN [ ANALYZE ] [ VERBOSE ] instrução
FORMAT { TEXT | XML | JSON | YAML }
O parametro ANALYZE faz o comando ser de fato executado, e não apenas planejado. O tempo total decorrido gasto em cada nó do plano (em milissegundos) e o número total de linhas retornadas são adicionados ao que é apresentado. Torna-se útil para avaliar se as estimativas do planejador estão próximas ao resultado final.
Agora vamos começar a entender os numeros atuais de saida de um EXPLAIN.
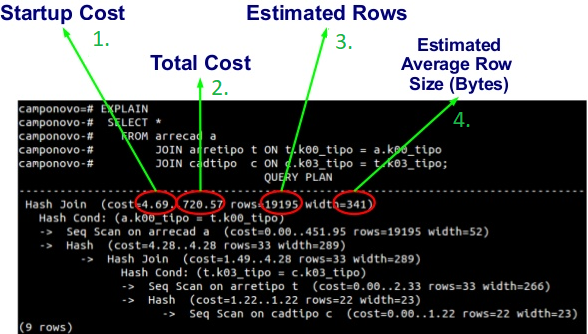
Imagem 1: Query plan
1-Startup Cost:
O custo de partida estimado (O tempo gasto antes da varredura da saída poder começar como, por exemplo, o tempo para fazer a ordenação em um nó de ordenação).
2-Total Cost:
O custo total estimado (Se todas as linhas forem buscadas, que pode não acontecer para uma consulta contendo a cláusula LIMIT não gastará o custo total, por exemplo).
3-Estimated Rows:
Número de linhas de saída estimado para este nó do plano (Novamente, apenas quando executado até o fim).
4-Estimated Average Row Size (bytes):
Largura média estimada (em bytes) das linhas de saída para este nó do plano.
Os custos são medidos em termos de unidades de páginas buscadas no disco (O esforço de CPU estimado é convertido em unidades de página de disco utilizando fatores estipulados altamente arbitrários. Se for desejado realizar experiências com estes fatores, deve ser consultada a lista de parâmetros de configuração em tempo de execução no Guia do Administrador do PostgreSQL.)
É importante perceber que o custo do nível mais alto inclui todos os custos de seus descendentes. O custo reflete apenas as partes com as quais o planejador/otimizador se preocupa. Em particular, o custo não considera o tempo gasto transmitindo o resultado para o cliente e, que pode ser um fator importante no computo do tempo total gasto, mas que o planejador ignora porque não é alterado pela mudança de plano (Todo plano correto produz o mesmo conjunto de linhas, acredita-se).
Linhas produzidas é um assunto delicado porque não é o número de linhas processadas/varridas pelo comando, geralmente é menos, refletindo a seletividade estimada das restrições de certas cláusulas WHERE aplicadas. Idealmente, as linhas de nível superior estimam de forma aproximada o número de linhas realmente retornadas, atualizadas ou excluídas pelo comando.
Os exemplos apresentados não representam a realidade de um ambiente com milhares e milhares linhas de dados, neste caso conseguimos reproduzir poucos exemplos de alteração quando mexemos em algum parâmetro do todo, podemos citar, quando criou o índice ou quando acrescentou um filtro.
Exemplos:
1-Busca simples em tb_liquidacao.

| 1-Start | 2-Total | 3-Rows | 4-Row Size | |
|---|---|---|---|---|
| Exemplo1 | 0 | 113.68 | 3468 | 16 |
Os valores desta tabela são os mesmos da figura acima (exemplo1), foram retirados da Query Plan. Neste caso, o Query Plan, apresenta uma busca sequencial.
2-Busca com uma condição (filtro em num_contrato).

| 1-Start | 2-Total | 3-Rows | 4-Row Size | |
|---|---|---|---|---|
| Exemplo1 | 0 | 113.68 | 3468 | 16 |
| Exemplo2 | 0 | 122.35 | 105 | 16 |
Analisando a tabela logo acima, vemos em linhas de saída(rows), 3468 para exemplo1 e 105 para exemplo2, enquanto que para o custo total 113.68 para exemplo1 e 122.35 para exemplo2. Porque o exemplo1 prevê mais linha no resultado em menor tempo? No exemplo1, ele vai varrer a tabela toda e apresentar os resultados, já no exemplo2, o motor de busca do banco de dados, além de fazer a mesma tarefa, ainda terá de avaliar se cada registro faz parte do filtro aplicado, ou seja, se pertence ao contrato '18000705'. Assim se justificaria um custo total maior para o exemplo2, com previsão de retornar menos linhas.
3-Relacionando a tabela tb_dados_gerais (num_contrato).
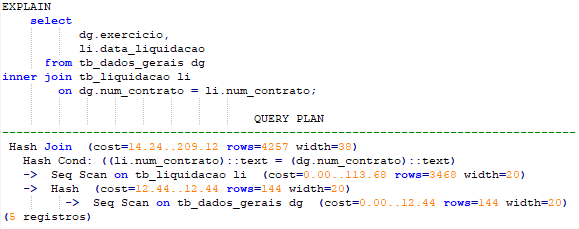
Olhe o Query Plan e veja que faz busca sequencial em ambas as tabelas.
4-Criação do indice (coluna num_contrato na tabela tb_liquidacao).

5-Busca com uma condição, agora com o índice.

| 1-Start | 2-Total | 3-Rows | 4-Row Size | |
|---|---|---|---|---|
| Exemplo2 | 0 | 122.35 | 105 | 16 |
| Exemplo5 | 5.09 | 89.59 | 105 | 16 |
Analisando o exemplo2 com o exemplo5, é a mesma consulta e, percebemos a queda do Custo Total para o último. No exemplo4 é apresentado a criação do índice. Neste caso, quando o exemplo5 é executado, o motor de busca do banco fará uso do índice, agora existente. Apesar de uma tabela com poucas linhas, já é possível um ganho no Custo Total da consulta.
6-Busca nas duas tabelas, ligando por num_contrato.

A criação do índice do exemplo4, não altera em nada neste caso, continua fazendo busca sequencial nas duas tabelas, veja Query Plan.
7-Relacionando as duas tabela e filtrando por num_contrato.
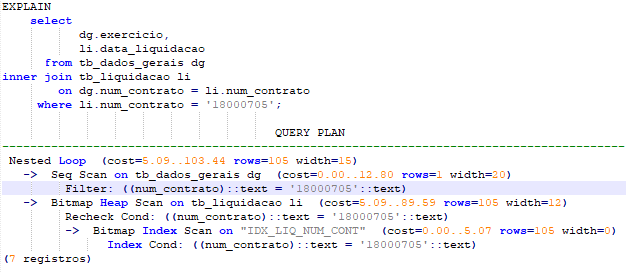
Neste exemplo podemos ver o Query Plan, que as duas tabelas fazem a busca sequencial, e o filtro para número de contrato usa o índice.
8-Criação do índice (coluna num_contrato na tabela tb_dados_gerais).

9-Relacionando as duas tabelas através da coluna num_contrato.
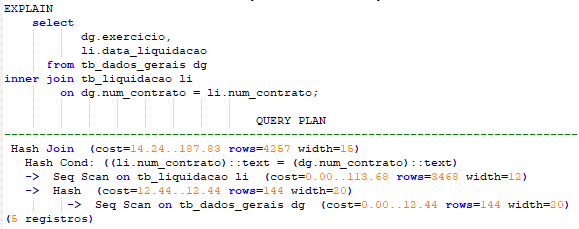
Mais um índice criado no exemplo8, e continua a busca sequencial em ambas as tabelas, veja Query Plan.
10-Não é apenas consulta. Um exemplo com 'update'.

Aqui no exemplo10, é apresentado o 'Query Plan' de uma alteração (‘update’). O Explain pode ser usado para outros comandos do banco, criação de alguns objetos, e na execução de ‘insert’ e ‘delete’.
11-Busca com agregação e ordenação, relacionando duas tabelas e com filtro.

O resultado já combinando vários temas, como: agregação, ordenação, leitura sequencial, uso de indice, filtro, etc.
12-Busca simples, com resultado em formato JSON.
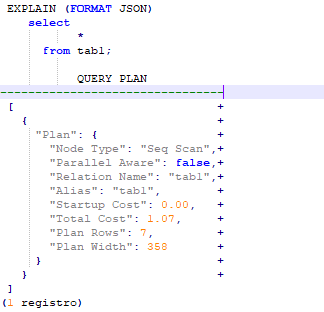
Os formatos possiveis atualmente são: TEXT | XML | JSON | YAML. Por default é o TEXT.
13-Busca simples, usando o parametro ANALYSE.
O parametro executa o comando e mostra os tempos reais de execução, e não apenas o plano de execução, como no caso do EXPLAIN sem o ANALYSE.
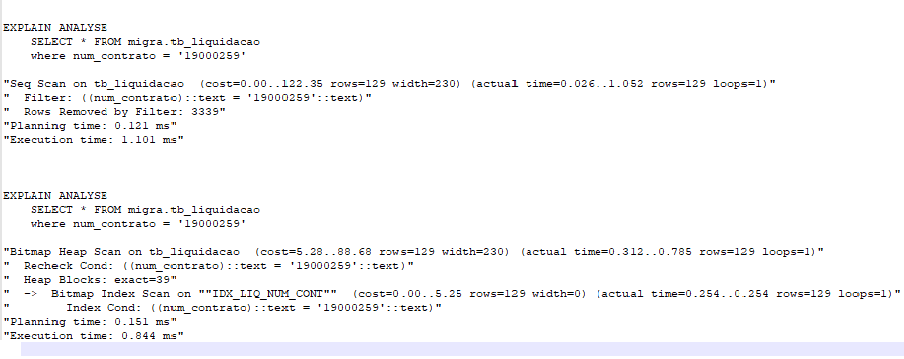
Pode-se notar um tempo de planejamento maior na segunda opção, de 0.121ms para 0.151ms, porém, o tempo de execução apresenta uma queda de 1.101ms para 0,844ms.
Está queda no resultado da execução da-se principalmente pelo uso do indice.
Concluindo.
Podemos concluir, dizendo que o assunto é amplo, e quem precisa enriquecer suas consultas com práticas que produzam melhores resultados, possa ter despertado um vislumbre do que é possível alcançar, com o aprofundamento no tema.
Recomendo que leia o artigo do amigo Eduardo, pois são tratados vários aspectos de grande importância para este tema, que não caberia redundar neste espaço.
link: http://tech.azi.com.br/otimizando-consultas-no-sql-server/
Neste material do Eduardo é tratado sobre o MS SqlServer, e se quiser ver o assunto no Oracle, o link é: http://tech.azi.com.br/plano-de-consulta-oracle/
Referencias:
https://www.postgresql.org/docs/current/using-explain.html
http://tecspace.com.br/paginas/aula/postgresql/guia/performance-tips.html
https://tecsinapse.tumblr.com/post/125165558784/entendendo-o-explain-do-postgres
https://pt.slideshare.net/fabriziomello/explicando-o-explain
Inscreva-se no { .aztech }
Receba as últimas postagens enviadas diretamente para sua caixa de entrada