Validação Cruzada (Cross Validation) — Avaliando seu modelo de forma clara e concisa
É de grande valia saber se seu modelo está preparado para receber qualquer parte do seu dataset que, “teoricamente” deveria representar a massa de dados do mundo real no contexto do seu problema, porém como todos sabemos nem sempre teoria e prática andam juntas. Para evitar problemas de generalização, a validação cruzada é lei quando se trata de modelos de predição.
Motivação
A validação cruzada é um método de reamostragem e tem como objetivo avaliar a capacidade de generalização do seu modelo. Em outras palavras, verificar o quão pronto seu modelo está para receber novos dados.
Dado um conjunto de dados, normalmente a distribuição entre treino e teste é feita da seguinte forma.

Fig. 1: separação em treino e teste
Sendo 70% do conjunto de treinamento para treino e o resto (30%), para teste, e na grande maioria das vezes a separação dos dados é feita de forma aleatória.
Agora vamos imaginar o cenário hipotético onde eu realizo a separação dos dados via código de forma aleatória, treino meu modelo e obtenho 80% de acurácia. Aviso meu chefe sobre precisão obtida e peço para marcar uma reunião com os executivos da empresa. No dia da reunião realizo o mesmo procedimento, mas por conta da aleatoriedade na separação dos dados o meu modelo apresenta apenas 68% de acurácia.
Essa variação na acurácia do modelo pode acontecer pelo fato de que nem sempre a separação dos dados é igual e eficaz a ponto de ter todos os cenários que o modelo precisa para aprender.
Na validação cruzada realizamos várias separações de treino e teste para avaliar o modelo em vários cenários de amostragem.

Fig. 2: iterações da validação cruzada
Exemplo
Requisitos
- Python 3.6 ou superior
- Pip
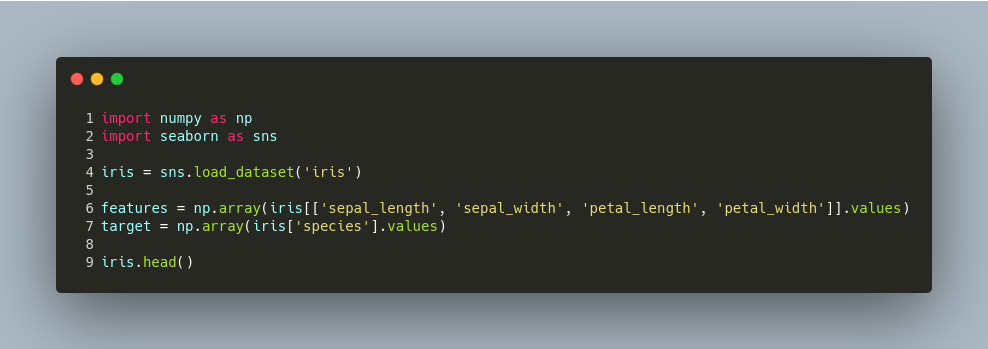
Vamos usar a biblioteca de aprendizado de máquina scikit-learn e a biblioteca de visualização de Seaborn apenas para carregar um dos vários datasets contidos nela. Portanto, essas podem ser instaladas via Pip com os seguintes comandos no terminal:
pip3 install seaborn
pip3 install -U scikit-learn
Preparando o dataset
Vamos usar o dataset “iris” presente na lib Seaborn. E um modelo de classificação Knn.
Pode ser inferido que vamos treinar um modelo que fará a predição da espécie de uma flor a partir suas características.
No código abaixo, estamos separando o dataset em duas variáveis que serão passadas para o nosso modelo. A variável features (equivalente a variável X), contendo todas os valores das características das plantas, a variável target (equivalente a variável Y), contendo as classes das flores.
Caso você esteja usando o Jupyter-Notebook, a saída esperada do comando iris.head(), é semelhante a imagem a seguir.
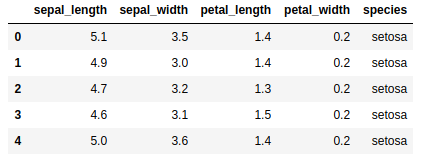
Fig. 3: Saída esperada do comando iris.head()
O código a abaixo cria uma instância do nosso modelo de classificação (linha 3), treina o modelo passando as características e as classes das flores (linha 5), e realiza uma predição com dados aleatórios (linha 7).

Abaixo definimos um método onde é feita a separação do nosso dataset três vezes,
para cada iteração realizamos o treino do modelo (linha 14), e a predição dos exemplos separados como teste (linha 15), por fim calculamos a acurácia e adicionamos o resultado do cálculo em um array. Ao final das iterações a média das acurácias (linha 21), representa uma métrica mais confiável e menos passiva de variância.

Neste exemplo utilizamos a técnica de amostragem estratificada, presente no sklearn, com intuito de preservar o balanceamento das classes.
Por fim podemos chamar o nosso método e atestar nossa métrica desejada.

Notebook do código completo aqui.
Caso tenham problemas ou dúvidas, estou disponível para ajudar.
Obrigado por chegar até aqui, até a próxima ;)
Inscreva-se no { .aztech }
Receba as últimas postagens enviadas diretamente para sua caixa de entrada